Why RAG Saves Companies $150M Annually: Real-World Examples
How major enterprises use Retrieval Augmented Generation to eliminate AI hallucinations and cut costs
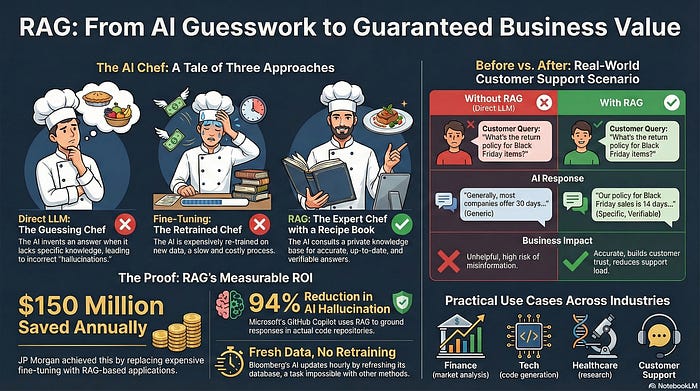
JP Morgan saved $150 million per year. Microsoft reduced AI hallucinations by 94%. Bloomberg updates its financial AI hourly without retraining models.
What do they all have in common? RAG architecture.
In my previous article, I explained what RAG is and how the three-phase architecture works. Now let’s see why it matters — through real examples that demonstrate the massive business impact.
The Restaurant Analogy: Understanding RAG in 60 Seconds
Imagine you’re a chef in Country A. A customer from Country B orders a European dish you’ve never made.
You have three options:
Option 1: Guess the recipe ❌
You don’t know how to make it, but you try anyway. The food is terrible.
This is AI hallucination — when an LLM generates confident-sounding but completely wrong answers because it wasn’t trained on the relevant data.
Option 2: Admit you don’t know 🤷
You tell the customer honestly: “I can’t make that dish.”
This is honest but unhelpful — the LLM refuses to answer because it lacks information.
Option 3: Check the recipe book ✅
You have a library of cookbooks. You look up the European dish, follow the recipe, and create something amazing.
This is RAG in action — the LLM references external knowledge sources (the “recipe books”) before generating its response.
The Technical Translation
In RAG systems, the vector database is your recipe book library:
Stores all company data (text, images, documents, videos)
Converts content into mathematical vectors using embeddings
Enables similarity search to find relevant information
Provides accurate, grounded responses instead of guesses
The three-step process remains the same:
Retrieval — Find relevant information from the vector database
Augmentation — Enrich with metadata (source, date, version)
Generation — Create accurate, contextualized responses
Real-World Example: Customer Support Transformation
Let’s compare how customer support works with and without RAG.
Customer question:
“What’s your return policy for items bought during the Black Friday sale?”
Without RAG ❌
Setup: Standard LLM used directly for customer support
Response:
“Generally, most companies offer 30-day returns, but policies may vary.”
Problems:
Generic and unhelpful
Not specific to this company
Based on general internet knowledge from training data
Customer still doesn’t know the actual policy
Why this happens: The LLM has no access to the company’s specific policy documents.
With RAG ✅
Setup: LLM + company policy database in vector storage
What happens behind the scenes:
RAG searches the company policy database
Finds matching policy documents using similarity search
Augments with metadata (version, date, source)
LLM summarizes the information
Response:
“Black Friday purchases have an extended 60-day return window (instead of our standard 30 days). This applies to all items purchased November 24–27, 2024. [Source: Holiday Return Policy v3.2, Updated Nov 2024]”
Advantages:
Company-specific and accurate
Includes version and date information
Reflects recent policy changes
Verifiable against source documents
Actually helps the customer
The Key Difference That Matters
RAG-powered responses work because:
Grounded in real data — Not guessing based on training data
Always current — Update the database, not the entire model
Verifiable — Every answer can be traced to source documents
Company-specific — Access to private, proprietary information
This is why enterprises are adopting RAG at scale.
Real-World Impact: The Numbers
JP Morgan: $150M Annual Savings
The challenge:
Research analysts needed AI assistance but fine-tuning models for financial data was prohibitively expensive.
The RAG solution:
Instead of fine-tuning (which requires retraining entire models), JP Morgan implemented RAG-based applications that query their proprietary financial databases.
Result:
$150 million saved annually by eliminating the need for expensive model retraining while providing analysts with accurate, up-to-date financial information.
Microsoft GitHub Copilot: 94% Reduction in Hallucinations
The problem:
Early versions of Copilot would generate code confidently even when it didn’t have proper knowledge of the libraries or frameworks being used.
The RAG implementation:
Copilot now references actual code repositories, documentation, and best practices before generating suggestions.
Result:
94% reduction in AI hallucinations. Code suggestions are grounded in real, working examples rather than educated guesses.
Bloomberg Financial AI: Hourly Updates
The challenge:
Financial markets change constantly. Traditional LLMs with static training data become outdated within hours.
The RAG approach:
Bloomberg updates their vector database hourly with new market data, news, and analysis.
Result:
An AI system that stays current without constant model retraining — something impossible with traditional approaches.
Healthcare Applications: Patient Safety
The critical requirement:
Medical AI systems cannot afford to hallucinate or provide outdated treatment protocols.
RAG’s role:
Medical databases, research papers, and treatment guidelines are stored in vector databases. AI assistants reference the latest protocols before making suggestions.
Impact:
Doctors get accurate, current medical information with clear source attribution — essential for patient safety and regulatory compliance.
Why Traditional Approaches Fail
Fine-tuning challenges:
Requires retraining entire models (expensive)
Time-consuming process (weeks or months)
Difficult to update frequently
Risk of catastrophic forgetting (losing previously learned information)
Training from scratch:
Prohibitively expensive (millions of dollars)
Requires massive compute resources
Not practical for most organizations
Still becomes outdated quickly
Direct LLM usage:
Generic responses
Hallucinations on company-specific queries
No access to private data
Cannot stay current with changing information
Why RAG Wins for Business Applications
Cost efficiency 💰
Update your database instead of retraining models. JP Morgan’s $150M savings proves the ROI.
Accuracy ✅
Ground responses in actual documents. Microsoft’s 94% hallucination reduction shows the impact.
Currency 🔄
Stay updated in real-time. Bloomberg’s hourly updates demonstrate the flexibility.
Transparency 🔍
Every answer includes source attribution. Critical for regulated industries like finance and healthcare.
Scalability 📈
Add new knowledge sources without architectural changes. Deploy across departments and use cases.
The Three Options Revisited
Remember our chef analogy? Here’s how it maps to AI strategies:
Option 1: Guessing (Direct LLM)
Fast but inaccurate. High risk of hallucinations. Not acceptable for business-critical applications.
Option 2: Admitting Ignorance (Constrained LLM)
Safe but unhelpful. Users don’t get the information they need.
Option 3: Checking References (RAG)
Accurate, helpful, and trustworthy. The enterprise standard.
For business applications where accuracy matters, RAG isn’t just better — it’s essential.
From Theory to Practice
Understanding the theory of RAG is step one. Implementing it effectively requires:
Choosing the right vector database
Options include Pinecone, Weaviate, Chroma, and Qdrant. Each has different strengths for speed, scale, and features.
Designing effective chunking strategies
How you break documents into pieces dramatically affects retrieval quality.
Optimizing embedding models
Different models work better for different types of content and domains.
Building retrieval pipelines
Balance between speed and accuracy. Too slow, and users won’t adopt it. Too fast but inaccurate, and you’re back to hallucinations.
Handling edge cases
What happens when no relevant information exists? How do you handle conflicting sources?
These implementation details are where RAG projects succeed or fail.
The Competitive Advantage
Companies implementing RAG effectively gain:
Operational efficiency — Automated support, research, and analysis
Cost reduction — Eliminate expensive retraining cycles
Competitive intelligence — AI systems that understand your business
Customer satisfaction — Accurate, helpful responses instead of generic answers
Regulatory compliance — Verifiable, source-backed information
The examples from JP Morgan, Microsoft, and Bloomberg aren’t outliers — they’re proof that RAG delivers measurable business value.
Key Takeaways
RAG solves the fundamental problems of traditional LLMs:
Hallucinations → Grounded in real documents
Outdated information → Update database, not models
Generic responses → Access to company-specific data
High costs → No expensive retraining needed
The results speak for themselves:
$150M saved (JP Morgan)
94% fewer hallucinations (Microsoft)
Hourly updates (Bloomberg)
For enterprises building AI applications, RAG isn’t optional — it’s the foundation of reliable, scalable AI systems.
This article was originally published on Substack.
Read on Substack