Understanding RAG: The Architecture Behind 80% of AI Applications
How Retrieval Augmented Generation solves the biggest limitation of large language models
You’ve probably used ChatGPT to answer questions. But have you ever wondered why it sometimes gives outdated information or can’t access your company’s internal documents?
That’s where RAG comes in.
Retrieval Augmented Generation (RAG) powers over 80% of business AI applications today. If you’re building with AI, understanding RAG isn’t optional — it’s essential.
In this article, you’ll learn what RAG is, why it matters, and how the three-phase architecture works in practice.
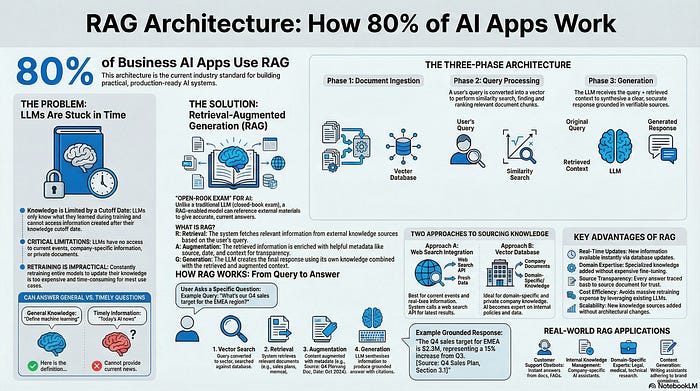
The Problem: LLMs Are Stuck in Time
Imagine you’re using an AI model trained on data through July 2023. Ask it “What is machine learning?” and you’ll get a perfect answer. ✅
Ask it “What’s today’s AI news?” and you’ll get nothing useful. ❌
Why? Large language models only know what they learned during training. They can’t access information beyond their knowledge cutoff date.
This creates three critical limitations:
No access to current events or recent developments
No knowledge of company-specific or domain-specific information
No ability to reference private documents or proprietary data
Traditional solutions meant retraining entire models — expensive, time-consuming, and impractical for most use cases.
The Solution: RAG Architecture
Think of RAG like this:
Traditional LLMs are students taking a closed-book exam. They only have what’s in their memory.
RAG-enabled models are students taking an open-book exam. They can reference external materials to give accurate, current answers.
RAG stands for three components that work together:
R = Retrieval 📥
Fetching relevant information from external sources
A = Augmentation ⚡
Enriching that information with helpful metadata
G = Generation 📝
Creating the final response using both the model’s knowledge and retrieved context
Two Approaches to External Knowledge
Approach 1: Web Search Integration
When you ask “What’s today’s AI news?” a RAG system can:
Recognize it needs current information
Call a web search API
Retrieve the latest results
Generate a response with up-to-date data
The LLM becomes tool-aware — it knows when to look things up rather than guess.
Approach 2: Vector Database for Domain Knowledge
Here’s where RAG gets powerful for business applications.
An employee asks: “What is our company’s remote work policy?”
The RAG flow:
Company documents are stored in a vector database (text converted to mathematical vectors)
The query searches this database using similarity metrics
The most relevant policy documents are retrieved
The LLM uses these documents as context
An accurate answer is generated based on actual company policies
This approach enables AI systems that are experts in your specific domain — without retraining foundation models.
The Three-Phase RAG Architecture
Most production RAG systems follow this pattern:
Phase 1: Document Ingestion
Your knowledge sources get processed and stored:
Documents are split into manageable chunks
Text is converted into vector embeddings
Vectors are stored in a specialized database
Metadata is attached (source, date, relevance)
This happens once during setup, then gets updated as new information arrives.
Phase 2: Query Processing
When a user asks a question:
The query is converted into a vector
A similarity search finds the most relevant document chunks
Multiple pieces of content might be retrieved for comprehensive context
Results are ranked by relevance
Think of this as a highly sophisticated search engine that understands meaning, not just keywords.
Phase 3: Generation
The final answer gets created:
The LLM receives both the query and retrieved context
It processes and synthesizes the information
A clear, accurate response is generated
The answer is grounded in real, verifiable sources
Why Augmentation Matters
The “A” in RAG is often overlooked but critical.
Basic retrieved content: “Remote work is allowed on Tuesdays and Thursdays.”
Augmented content: “Remote work is allowed on Tuesdays and Thursdays. [Source: Employee Handbook v2.3, Updated: Jan 2024, Section 4.2]”
Adding metadata makes responses:
Verifiable against source documents
Trustworthy with clear attribution
More useful with context about recency
This transparency is what makes RAG suitable for enterprise applications where accuracy matters.
Real-World Applications
RAG architecture powers:
Customer Support Chatbots
Access to product documentation, FAQs, and support tickets
Internal Knowledge Management
Company-specific AI assistants that understand your policies and procedures
Domain-Specific Experts
Legal research tools, medical assistants, technical documentation helpers
Content Generation
Writing assistants that reference your style guides and brand materials
The common thread: AI systems that combine general language understanding with specific, accurate knowledge.
Key Advantages Over Other Approaches
Real-time updates 🔄
Update your vector database, not your entire model. New information becomes available instantly.
Domain expertise 🎓
Load specialized knowledge without expensive fine-tuning or retraining.
Source transparency 🔒
Every answer can be traced back to source documents, building trust in AI-generated content.
Cost efficiency 💰
No need to retrain foundation models. Use existing LLMs with your data.
Scalability 📈
Add new knowledge sources without architectural changes.
The Complete RAG Flow in Practice
Here’s a real example:
User query: “What’s our Q4 sales target for the EMEA region?”
Step 1: Query converted to vector
Step 2: Vector database searched for similar content
Step 3: Relevant documents retrieved (sales plans, regional targets)
Step 4: Content augmented with metadata (source: Q4 Planning Doc, date: Oct 2024)
Step 5: LLM generates: “The Q4 sales target for EMEA is $2.3M, representing a 15% increase from Q3. [Source: Q4 Sales Plan, Section 3.1]”
The answer is accurate, current, and verifiable.
What’s Next
Understanding RAG architecture is the foundation. Building production RAG systems requires:
Choosing the right vector database (Pinecone, Weaviate, Chroma)
Implementing effective chunking strategies
Optimizing embedding models for your use case
Designing retrieval pipelines that balance speed and accuracy
Handling edge cases and improving relevance
Each phase — ingestion, query processing, and generation — has depth worth exploring.
Key Takeaways
RAG solves the fundamental limitation of LLMs: being stuck in time with no access to external knowledge.
The three components work together:
Retrieval finds relevant information
Augmentation adds helpful context and metadata
Generation creates accurate, grounded responses
This architecture enables AI applications that are practical, trustworthy, and production-ready.
With over 80% of business AI applications using RAG, understanding this pattern is essential for anyone building with generative AI.
This article was originally published on Substack.
Read on Substack