Prompt Engineering vs Fine-tuning vs RAG: Which AI Approach Should You Choose?
A technical comparison to help you pick the right strategy for your use case — and avoid expensive mistakes
You’re building an AI application. Should you use prompt engineering, fine-tune a model, or implement RAG?
Choose wrong, and you’ll either waste money on unnecessary infrastructure or deliver subpar results. Choose right, and you’ll build something that scales efficiently.
This isn’t a theoretical debate it’s a practical decision that affects your timeline, budget, and product quality. Let’s break down each approach so you can make the right call.
The Core Question Every AI Builder Faces
Many developers struggle with this decision because the approaches seem overlapping. After all, they’re all ways to make LLMs more useful for specific tasks.
But they solve fundamentally different problems:
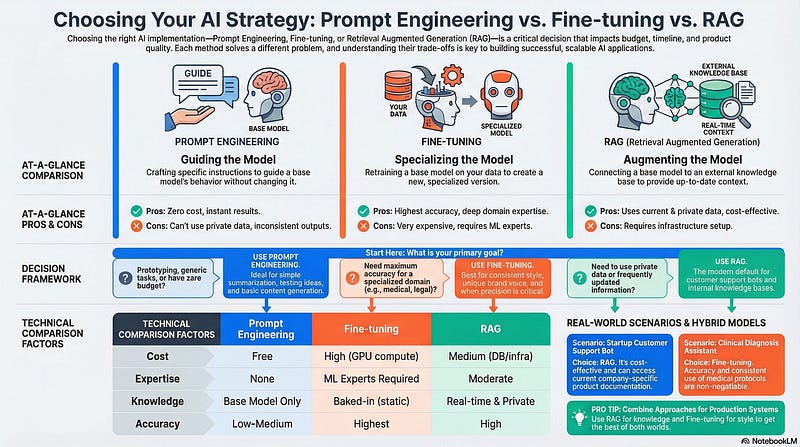
Prompt Engineering = Guiding a base model with instructions
Fine-tuning = Creating a specialized model through training
RAG = Augmenting a base model with external knowledge
Understanding when to use each approach is what separates successful AI implementations from expensive failures.
Prompt Engineering: The Natural Language Approach
How It Works
Prompt engineering means giving specific instructions to a base LLM without changing the model itself.
Example:
Prompt: “Act as a chef and provide a recipe”
Input: “How do I prepare pizza?”
Output: [Recipe formatted as if written by a professional chef]The model remains completely unchanged. You’re simply crafting better questions and providing clearer context.
Core Properties
No model modifications — Parameters stay the same
Instruction-based — Uses natural language to guide behavior
Context-dependent — Ambiguous prompts produce poor results
Instant results — No training or setup time required
Strengths ✅
No technical expertise required
Anyone who can write clear instructions can do prompt engineering. No ML background needed.
Instant deployment
Change your prompt, get different results immediately. Perfect for rapid iteration.
Zero training costs
Completely free to experiment and modify. No GPU rental or training time.
Platform-agnostic
Works with any LLM — GPT-4, Claude, Llama, or any other model.
Limitations ❌
Stuck with base knowledge
The model only knows what it learned during training. Can’t access company-specific or current information.
Inconsistent results
Small prompt changes can yield wildly different outputs. Hard to guarantee consistent behavior.
Token limits
Context windows constrain complexity. You can’t provide extensive documentation in every prompt.
No new knowledge
Cannot overcome the model’s training data cutoff. Outdated information stays outdated.
When to Use Prompt Engineering
✅ Quick prototyping — Test ideas before committing to infrastructure
✅ Generic tasks — Summarization, translation, basic Q&A
✅ Small-scale applications — Low-volume use cases
✅ Public-facing content — Tasks using publicly available information
❌ Avoid for: Company-specific work requiring domain expertise or consistent brand voice
Fine-tuning: The Specialized Model Approach
How It Works
Fine-tuning means retraining a base LLM on domain-specific data to create a specialized version.
The process modifies the model’s weights permanently, baking in specific knowledge and behavior patterns.
Example use case:
A company chatbot that always responds: “Welcome to XYZ Company! How may I assist you with our services today?”
This consistent behavior is trained into the model, not prompted every time.
Core Properties
Domain-specific training — Model learns from your data
Permanent weight changes — Creates a new specialized version
Supervised learning — Trained on labeled examples
Optimized behavior — Consistently performs specific tasks
Technical Implementation
Modern fine-tuning uses efficient methods like:
LoRA (Low-Rank Adaptation) — Updates model parameters efficiently
QLoRA — Quantized version for reduced memory requirements
These techniques minimize computational costs while still achieving strong results.
Strengths ✅
Deep specialization
The model becomes an expert in your specific domain — legal, medical, financial, whatever you train it on.
Consistent behavior
No prompt engineering needed for basic behavior. The model “knows” how to act.
Learns new styles
Can adopt specific writing styles, tone, and domain vocabulary naturally.
Best for domain expertise
Superior performance on specialized tasks compared to prompt engineering.
Limitations ❌
Expensive
GPU rental costs make this prohibitive for startups and small projects. We’re talking thousands of dollars for proper training.
Requires ML expertise
You need people who understand model training, hyperparameter tuning, and evaluation metrics.
Regular retraining needed
As your data or requirements change, you must retrain — an expensive, time-consuming cycle.
Not startup-friendly
Limited budgets can’t sustain ongoing GPU costs for frequent model updates.
When to Use Fine-tuning
✅ Specific style requirements — Unique brand voice or behavior patterns
✅ High-volume consistent tasks — Processing thousands of similar requests
✅ Critical accuracy — Medical, legal, or financial applications where precision matters
✅ Domain-specific applications — Deep expertise in specialized fields
❌ Avoid for: Startups with limited budgets, frequently changing requirements, or real-time data needs
RAG: The Knowledge Augmentation Approach
How It Works
RAG (Retrieval Augmented Generation) teaches the LLM by giving it access to external knowledge sources.
The process:
Store documents in a vector database
User submits a query
System performs similarity search to find relevant documents
Retrieved documents are summarized and augmented with metadata
LLM generates response using this retrieved context
The base model never changes. It just gets better information to work with.
Core Properties
External knowledge storage — Vector databases, APIs, document repositories
Similarity-based retrieval — Finds relevant content for each query
Context augmentation — Enriches LLM input with retrieved documents
No model training — Uses base LLM without modifications
Technical Architecture
RAG systems can use multiple knowledge sources:
Vector databases (Pinecone, Weaviate, Chroma) — Primary method
Third-party APIs — Real-time data sources
Document repositories — Company files, PDFs, documentation
Cloud-based storage — Scalable vector databases via API
The retrieval process uses similarity metrics to match queries with relevant content before the LLM generates its response.
Strengths ✅
Always up-to-date
Update your knowledge base without retraining the model. Add new documents instantly.
No training required
Uses the base LLM as-is. No expensive GPU time or ML expertise needed.
Cost-effective
Infrastructure costs are far lower than ongoing model training. Scales efficiently.
Handles private data
Your proprietary information stays in your secure vector database, never exposed during model training.
Good accuracy
Not quite as high as fine-tuning in specialized domains, but improving rapidly with advanced RAG techniques.
Limitations ❌
Infrastructure setup
Need to implement vector database, embedding pipeline, and retrieval system.
Retrieval quality matters
Bad document retrieval = bad outputs. The system is only as good as what it finds.
Context window limits
LLM token limits constrain how much retrieved content you can include per query.
When to Use RAG
✅ Customer support — Real-time access to product documentation and policies
✅ Frequently updated information — News, market data, evolving knowledge bases
✅ Private data handling — Company documents, proprietary information
✅ Real-time integration — Information that changes regularly
❌ Avoid for: Maximum accuracy requirements in life-critical applications, or if simple infrastructure is preferred
The Decision Matrix: Choosing Your Approach
Here’s how to decide based on your specific situation:
Choose Prompt Engineering When:
Building proofs of concept or MVPs
Tasks are generic and well-suited to base model knowledge
You need results immediately
No budget for infrastructure or training
Team lacks ML expertise
Example: A content summarization tool for public articles
Choose Fine-tuning When:
Domain expertise is critical (legal, medical, financial)
Consistent behavior and style are non-negotiable
High-volume repetitive tasks justify training costs
Accuracy requirements are extremely high
You have ML expertise and budget for ongoing training
Example: A medical diagnosis assistant that must follow specific clinical protocols
Choose RAG When:
Information updates frequently
Working with private or proprietary data
Cost-effectiveness is important
Real-time data access is required
Good accuracy is sufficient (not perfect required)
Example: Internal company knowledge base assistant
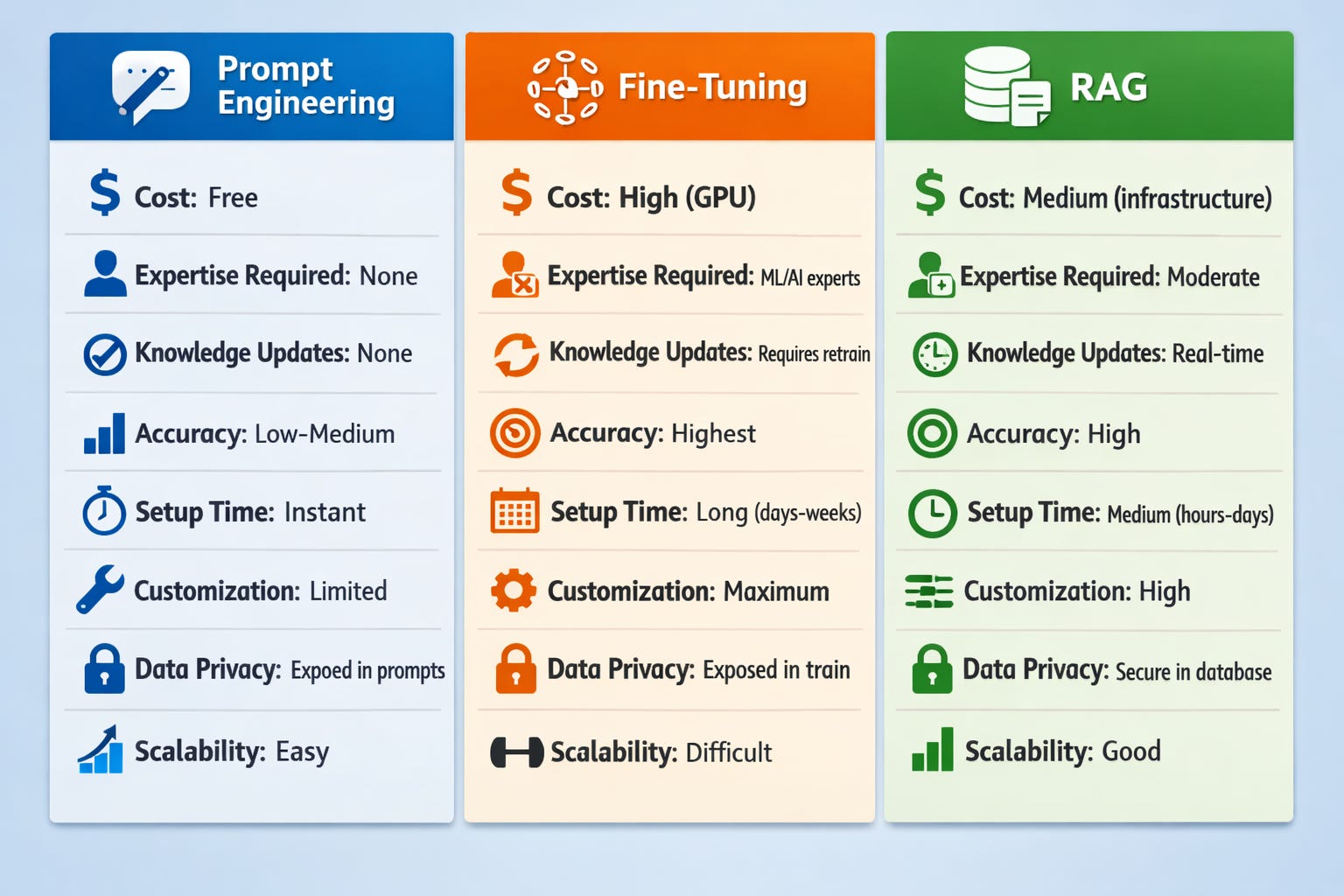
Technical Comparison at a Glance
Real-World Decision Examples
Scenario 1: Startup Building Customer Support Bot
Requirements:
Access to product documentation
Handle company-specific questions
Limited budget (<$10k)
Small team without ML expertise
Best choice: RAG
Why? Cost-effective, handles company-specific knowledge, no ML expertise needed, can update docs without retraining.
Scenario 2: Healthcare Company Building Clinical Assistant
Requirements:
Extremely high accuracy requirements
Consistent medical terminology and protocols
Regulatory compliance critical
Budget for specialized development
Best choice: Fine-tuning
Why? Accuracy is non-negotiable, consistent behavior required, domain expertise justifies cost, regulatory needs demand control.
Scenario 3: Content Agency Building Writing Assistant
Requirements:
Generate blog post outlines
Generic writing tasks
Fast iteration on outputs
No budget for infrastructure
Best choice: Prompt Engineering
Why? Generic task, no domain-specific knowledge needed, instant results, zero cost.
Combining Approaches
In practice, you often use multiple approaches together:
Prompt Engineering + RAG
Use prompts to structure how the LLM uses retrieved context. Common combination for production systems.
Fine-tuning + RAG
Fine-tune for style and behavior, use RAG for up-to-date knowledge. Best of both worlds for enterprise applications with budget.
Prompt Engineering + Fine-tuning
Fine-tune for domain expertise, use prompts for task-specific instructions. Less common but useful in some cases.
The Evolution: Where Things Are Heading
Prompt engineering is getting more sophisticated with techniques like chain-of-thought prompting and few-shot learning.
Fine-tuning is becoming more accessible with efficient methods like LoRA and QLoRA reducing costs.
RAG is improving dramatically with advanced retrieval techniques, better embeddings, and hybrid search approaches.
The trend: RAG is becoming the default for most business applications due to its balance of cost, flexibility, and accuracy.
Key Takeaways
Prompt Engineering
Best for: Quick prototyping, generic tasks, zero-budget scenarios
Limitation: Stuck with base model knowledge
Fine-tuning
Best for: Domain expertise, consistent behavior, critical accuracy
Limitation: Expensive and requires ML expertise
RAG
Best for: Private data, frequent updates, cost-effective accuracy
Limitation: Requires infrastructure setup
The decision depends on your specific requirements for accuracy, cost, update frequency, and technical resources.
For most startups and business applications, RAG offers the best balance. For specialized domains requiring maximum accuracy, fine-tuning is worth the investment. For experimentation and generic tasks, prompt engineering gets you moving fast.
This article was originally published on Substack.
Read on Substack